Si uno de los temas que definirá el futuro de las organizaciones es el machine learning las administraciones públicas no son una excepción. Vamos encontrando casos cada vez más interesantes, aplicados a cuestiones como la auditoría, la prevención de incendios o, muy de actualidad, la previsión de la evolución del COVID. La cuestión es que, dentro de esta tecnología encontramos una serie de herramientas y modelos diferenciados… La cuestión es que un conocimiento de los mismos nos debe llevar a dos cuestiones fundamentales: encontrar oportunidades de aplicación y seleccionar la mejor opción dentro de las existentes. En este artículo os cuento un poco los principales tipos que hay y las áreas de aplicación más adecuadas que podemos encontrar en el sector público.

Modelos de machine learning para administraciones públicas
Lo primero que tenemos que considerar es que hay tres grandes bloques de modelos de machine learning. En primer lugar hay que entender que lo que define al machine learning es la capacidad de los ordenadores de aprender a partir de una serie de elementos para extraer conclusiones aplicables a otros diferentes. Esto hace que tengamos dos grandes condiciones sobre los que pivotan los modelos posibles.
- Que dispongamos de resultados a partir de los que aprender. Cuando enseñamos al algoritmo los datos ¿incluyen estos el resultado que esperamos o no? Según esto, hablaremos de aprendizaje supervisado (con los resultados) o no supervisado (sin ellos).
- De la manera que la máquina aprende. Si este aprendizaje se basa en la extrapolación de datos y la inferencia de los mismos, o si se basa en una evaluación directa de los resultados. Mientras que el primer caso se aplica a los modelos supervisados y no supervisados, el segundo caso es el modelo de «aprendizaje de refuerzo»
Ahora vamos a ver en qué consiste cada uno de ellos.
Modelos supervisados
Los modelos supervisados son aquellos en los que los datos a partir de los que se aprende, incluyen el resultado. Es decir, si, por ejemplo, tenemos datos de recaudación en una ciudad e indicadores macroeconómicos, confiamos en que a partir de la observación, podemos suponer qué recaudación habrá los próximos años, o cómo afectará la instalación de una nueva industria. De esta manera, la máquina puede extraer conclusiones en su entrenamiento y, luego, estimar el resultado. Es la manera más directa de aplicar el machine learning. Dentro de este modelo hay dos principales prácticas.
Regresiones
Las regresiones se basan en establecer relaciones matemáticas entre diferentes variables (atributos o features) con un valor numérico definido (etiqueta). Es decir, sabes los valores de los atributos y la etiqueta y el algoritmo estima lo que pesa cada uno de ellos para calcularlo en el futuro. A partir de ahí, sabiendo esos atributos, sabremos el resultado final. Las regresiones han tenido últimamente una aplicación directa en la estimación de la evolución del COVID. Otros casos en los que aplica son:
- Evolución demográfica. Conocer qué aspectos influyen en cómo va a variar la población en una ciudad tiene una aplicación directa en cuestiones como, por ejemplo, ver qué equipos municipales hacen falta, el tipo de infraestructuras o servicios, o la previsión de vivienda, por poner unos pocos ejemplos.
- Estudios de mercados públicos. A partir del análisis de la contratación y del sector económico, estimar cuáles son los precios o concurrentes habituales para una licitación reduciría el tiro a ciegas que puede hacer una administración al hacer una licitación. Sobre este tema, espero contaros algo en nuestro proyecto de contratos inteligentes
- Predicciones económicas. La valoración de la situación económica puede permitir establecer medidas de corrección, estímulo o contención según sea necesario
- Eficacia de la comunicación pública. Si estudiamos la evolución de uso de recursos o de cambios de actitud a partir de esfuerzos de comunicación pública, podremos saber hasta qué punto vale la pena hacerlo, o cómo mejorarlo a futuro.
Estos son solo unos pocos ejemplos, de todo lo que se puede hacer.
Clasificaciones: separando el grano de la paja.
El segundo modelo (y casi que mi favorito), es la clasificación. En ella, a partir de una serie de datos decidimos si una entidad corresponde a un grupo o a otro. El ejemplo que se pone más a menudo es el spam: a partir de ciertos criterios (que se van actualizando con el aprendizaje), el servidor de correo considera si un correo es basura o no lo es. De nuevo, estamos hablando generalmente de aprendizajes supervisados (por ejemplo, recordad cuando hace años se invitaba a clasificar correos como spam: estábamos entrenando esos algoritmos, dándoles entidades en las que fijarse). En todo caso, estos modelos tienen las siguientes aplicaciones (por poner algunos casos).
- El fraude fiscal: este es uno de los elementos más consolidados en el sector privado. A partir de diferentes datos definir si un uso de una tarjeta es fraudulento o no, y esto se aplica a la estimación de riesgo de fraude etc. En el caso de la inspección fiscal (o de la detección de la corrupción) podría ser de gran utilidad, aunque tenemos la limitación de que es muy difícil etiquetar comportamientos que no sabes (cómo sabes que una práctica es fraudulenta si aún no se ha descubierto).
- La clasificación de hogares de acogida. Hace unos días escuchaba una entrevista a una responsable de los hogares de acogida en EEUU y decía que estaban trabajando para estimar la idoneidad de los hogares reduciendo la lentitud y las restricciones ciudadanas.
- Valoración de candidaturas para ayudas o subvenciones. Partir de una serie de datos para estimar si un negocio o empresa opta en buenas condiciones para una ayuda es algo que hacen los bancos y que podrían hacer las AAPP, más ahora con los fondos Next Generation.
Dejo fuera casi que la estrella de estos algoritmos, que es el reconocimiento facial y que a base de apps, selfis, filtros, y demás entrenamos por el día para que, por la noche, nos escandalice el gran hermano en el que estamos.
Modelos no supervisados
Los modelos no supervisados parten de dejar los datos a la máquina y que ella saque sus propias conclusiones. Esto hace por un lado más sorprendentes y «libres» sus respuestas. En todo caso, también tienen algunas limitaciones de aplicación directa, pero, en muchos casos, son muy útiles para los modelos supervisados.
Reducción de dimensionalidad
La reducción de dimensionalidad es un mecanismo a partir del cual un algoritmo reduce los atributos necesarios para extraer conclusiones. Esto, que parece poco útil para quien no esté familiarizado con estas cosas, es fundamental, dado que los modelos supervisados requieren cientos o miles de atributos, lo que es tiempo, dinero y recursos. Usar estos mecanismos permite que podamos hacer más y mejores usos supervisados. Entre los casos de aplicación de dimensionalidad tenemos:
- Visualización de grandes datos. Una ventaja que tienen estos sistemas es que estructuran la información de manera que sea más o menos inteligible para ver si tiene sentido. Por ejemplo, permite ver si, tras clasificar cientos de fotos, las que tienen temáticas parecidas están juntas (y el algoritmo las agrupa bien) o no
- Compresión relevante: otra posibilidad es la de comprimir los cientos de atributos que necesitamos para saber si alguien va a defraudar impuestos para poder aplicarlo a más personas más rápido en lugar de esperar meses o años.
- Descubrimiento de estructuras. Una manera muy útil de trabajar es coger una serie de datos del tipo que sean y ver si se encuentran patrones comunes. Esto permite, por ejemplo, detectar prácticas consolidadas o extrapolables, por ejemplo, en técnica legislativa o redacción de tendencias y tratarlos de manera conjunta.
Clusterizado
El clusterizado parte de recoger una serie de entidades y ver de qué manera se pueden agrupar entre ellas sin saber lo que tienen en común. Por ejemplo, coger el consumo de luz de varias ciudades a lo largo de un año y ver cuáles tienen comportamientos similares para ver qué tipo de política energética seguir. El clusterizado es muy prácitco para encontrar lo que no sabías que existía, o lo que no ves la manera de separar de manera simple, como por ejemplo.
- Proposición de ayudas o servicios. Si detectamos que cierto tipo de hogares tienen un comportamiento similar, es posible que podamos ofrecerles servicios comunes. Algo parecido se hace con las recomendaciones de marketing
- Segmentación de públicos o áreas. Si encontramos barrios o regiones que están en condiciones socioeconómicas similares, podríamos aplicar políticas de desarrollo económico muy parecido.
- Clasificación de textos. Buscar un montón de textos normativos o convocatorias y encontrar clausulas de condiciones muy similares o que toquen temas relacionados puede facilitar la búsqueda de precedentes, analogías o similitudes sobre un mismo tema.
El clusterizado es especialmente útil para encontrar nuevos atributos para mejorar los modelos supervisados, o buscar nuevos enfoques que para una aplicación directa en sí misma.
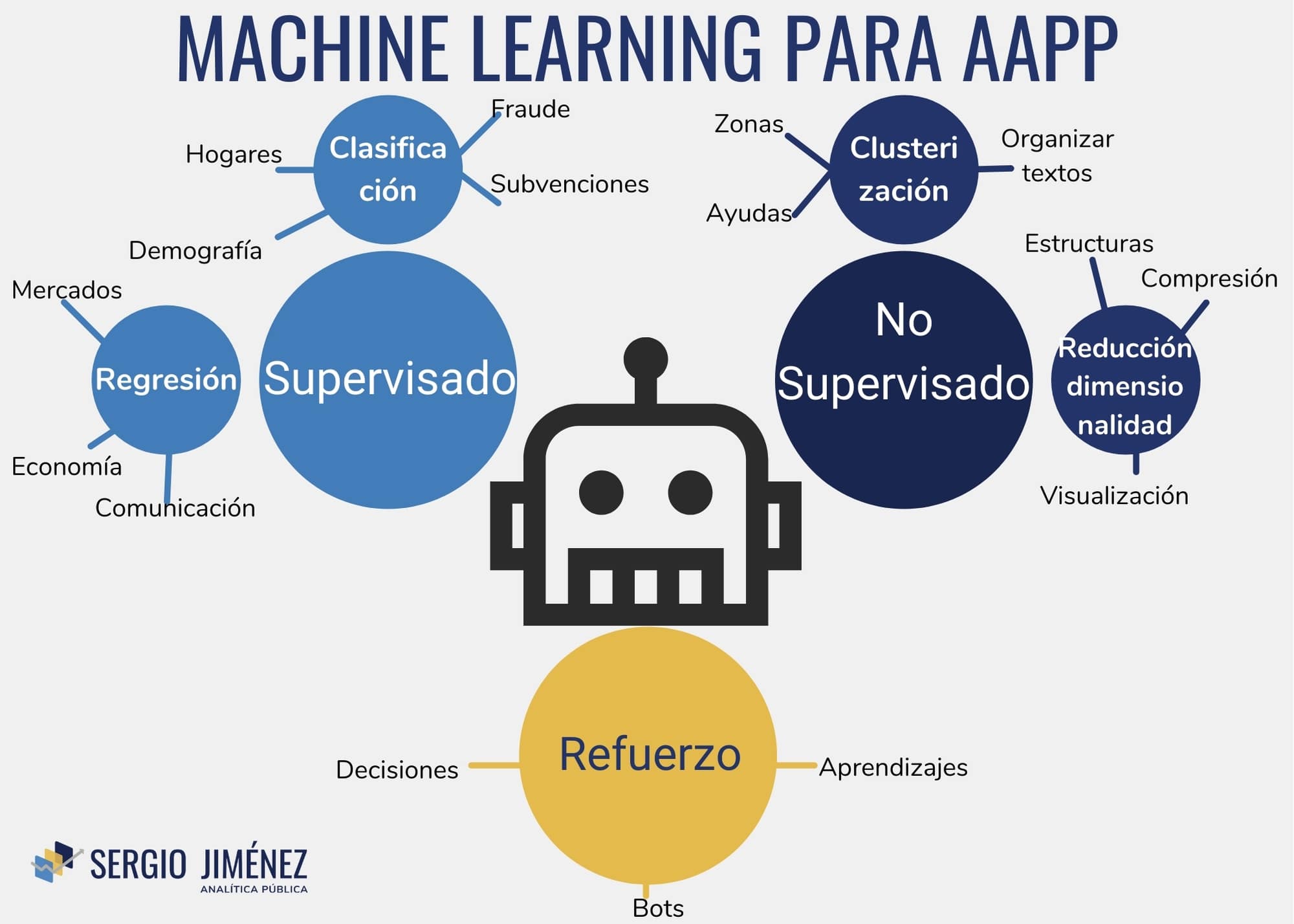
Aprendizaje reforzado
El aprendizaje reforzado es quizá el mecanismo más complejo de Machine Learning y el más parecido a la «inteligencia» tal y como la entendemos. En este caso, dejamos que un sistema aprenda a tomar sus decisiones indicándole a posteriori si su decisión es un éxito o un fallo. A partir de ahí, él hace sus ineferencias y vuelve a empezar. Este es el modelo usado para Alpha Go, la máquina de Google que ganó al campeón del mundo de Go, o de esa IA de microsoft que a los pocos días de ir a twitter se hizo racista y machista. En todo caso, las aplicaciones más evidentes serían:
- Toma de decisiones a tiempo real. El sistema decide, por ejemplo, como ajustar el tráfico de la ciudad a partir de los datos que obtiene de las cámaras.
- Habilidades de aprendizaje: Clasificación de casos de riesgo a partir de los datos médicos de una persona para ajustar las listas de espera quirúrgica
- Uso de robots, como por ejemplo drones de control de tráfico o seguridad o los propios bots conversacionales.
Este es, como decía, el modelo más «identificable» como Inteligencia Artificial, pero también el que requiere una mayor inversión en computación y, diría, que el que ha tenido resultados más estrepitosos, tanto de éxito como de fracaso.
Una visión de conjunto para el machine learning en las administraciones públicas
En todo caso, hemos visto que hay cientos de posibilidades (esto son solo unos pocos ejemplos) de aplicación del machine learning a las administraciones públicas. En buena lógica, lo más rápido y aplicable son los modelos supervisados que, además, tienen ya bastantes aplicaciones. Sin embargo, hay que considerar que todo esto debería parecer muchísimo más a una «industria» o «arte» que a un conjunto de aplicaciones individuales. Es decir, hay que entender que muchos modelos no supervisados pueden tener un impacto enorme a la hora de desarrollar o mejorar modelos supervisados.
Igualmente, la casuística del sector público es enorme, pero quizá no tan diferenciada como para que podamos integrar y aprender de diferentes modelos y enfoques a lo largo de los próximos años. Esto requiere que, igual que han hecho otros sectores, como la banca o los seguros, inviertan de manera continua y generen un conocimiento que nos haga crecer a todos.

{kind=link}